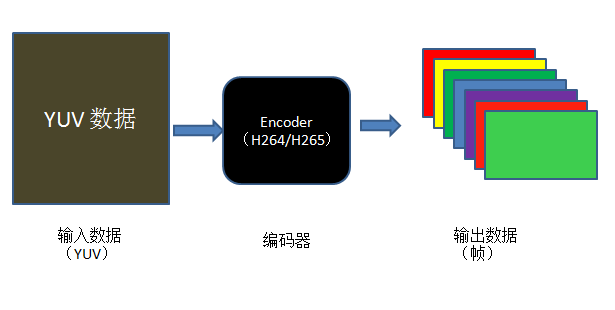
//allocate AVFrame structAVFrame*frame=NULL;frame=av_frame_alloc();if(!frame){printf("Alloc Frame Fail\n");return-1;}//fill AVFrame struct fieldsframe->width=width;frame->height=height;frame->pix_fmt=AV_PIX_FMT_YUV420P;//allocate AVFrame data buffers field pointret=av_image_alloc(frame->data,frame->linesize,frame->width,frame->height,frame->pix_fmt,32);if(ret<0){printf("Alloc Fail\n");return-1;}//write input file data to frame->data bufferfread(frame->data[0],1,frame->width*frame->height,pInput_File);...av_frame_free(frame);
AVCodec*codec=NULL;AVCodecContext*codecCtx=NULL;//register all encoder and decoderavcodec_register_all();//find the encodercodec=avcodec_find_encoder(codec_id);if(!codec){printf("Could Not Find the Encoder\n");return-1;}//allocate the AVCodecContext and fill it's fieldscodecCtx=avcodec_alloc_context3(codec);if(!codecCtx){printf("Alloc AVCodecCtx Fail\n");return-1;}codecCtx->bit_rate=4000000;codecCtx->width=frameWidth;codecCtx->height=frameHeight;codecCtx->time_base=(AVRational){1,25};//open the encoderif(avcodec_open2(codecCtx,codec,NULL)<0){printf("Open Encoder Fail\n");}
存放编码数据的结构体为 AVPacket,使用之前要对该结构体进行初始化,初始化函数为av_init_packet(AVPacket *pkt),该函数会初始化 AVPacket 结构体中一些字段为默认值,但它不会设置其中的 data 和 size 字段,需要单独初始化,如果此处将 data 设为 NULL、size 设为 0,编码器会自动填充这两个字段。
AVPacketpkt;//init AVPacketav_init_packet(&pkt);pkt.data=NULL;pkt.size=0;//encode the imageret=avcodec_encode_video2(codecCtx,&pkt,frame,&got_output);if(ret<0){printf("Encode Fail\n");return-1;}if(got_output){fwrite(pkt.data,1,pkt.size,pOutput_File);}
//open input fileFILE*pInput_File=fopen(Input_FileName,"rb+");if(!pInput_File){printf("Open Input File Fail\n");return-1;}//read compressed bitstream form file to bufferuDataSize=fread(inbuf,1,INBUF_SIZE,pInput_File);if(uDataSize==0){//decode finishreturn-1;}//decode the data in the buffer to AVPacket.datawhile(uDataSize>0){len=av_parser_parse2(pCodecParserCtx,codecCtx,&(pkt.data),&(pkt.size),pDataPtr,uDataSize,AV_NOPTS_VALUE,AV_NOPTS_VALUE,AV_NOPTS_VALUE);uDataSize-=len;uDataPtr+=len;if(pkt.size==0)continue;decode_frame(pkt.data,pkt.size);}
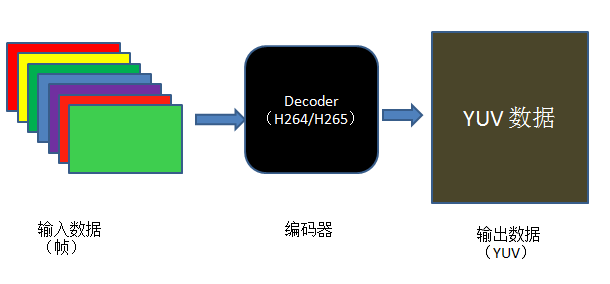
AVFrame*frame=NULL;AVCodec*codec=NULL;AVCodecContext*codecCtx=NULL;AVCodecParserContext*pCodecParserCtx=NULL;//register all encoder and decoderavcodec_register_all();//Allocate AVFrame to Store the Decode Dataframe=av_frame_alloc();if(!frame){printf("Alloc Frame Fail\n");return-1;}//Find the AVCodec Depending on the CODEC_IDcodec=avcodec_find_decoder(AV_CODEC_ID_H264);if(!codec){printf("Find the Decoder Fail\n");return-1;}//Allocate the AVCodecContext codecCtx=avcodec_alloc_context3(codec);if(!codecCtx){printf("Alloc AVCodecCtx Fail\n");return-1;}//Allocate the AVCodecParserContext pCodecParserCtx=av_parser_init(AV_CODEC_ID_H264);if(!pCodecParserCtx){printf("Alloc AVCodecParserContext Fail\n");return-1;}//Open the Decoderif(avcodec_open2(codecCtx,codec,NULL)<0){printf("Could not Open the Decoder\n");return-1;}//read compressed bitstream form file to bufferuDataSize=fread(inbuf,1,INBUF_SIZE,pInput_File);if(uDataSize==0){//decode finishreturn-1;}//decode the data in the buffer to AVPacket.datawhile(uDataSize>0){len=av_parser_parse2(pCodecParserCtx,codecCtx,&(pkt.data),&(pkt.size),pDataPtr,uDataSize,AV_NOPTS_VALUE,AV_NOPTS_VALUE,AV_NOPTS_VALUE);uDataSize-=len;uDataPtr+=len;if(pkt.size==0)continue;//decode startavcodec_decode_video2(codecCtx,frame,&got_frame,pkt);}
注意,上面解码的过程中,针对具体的实现,可能要做一些具体参数上的调整,此处只是理清解码的流程。
对于输出数据。解码完成后,解码出来的像素域的数据存放在 AVFrame 的 data 字段内,只需要将该字段内存放的数据之间写文件到输出文件即可。解码函数avcodec_decode_video2函数完成整个解码过程,对于它简单介绍如下:
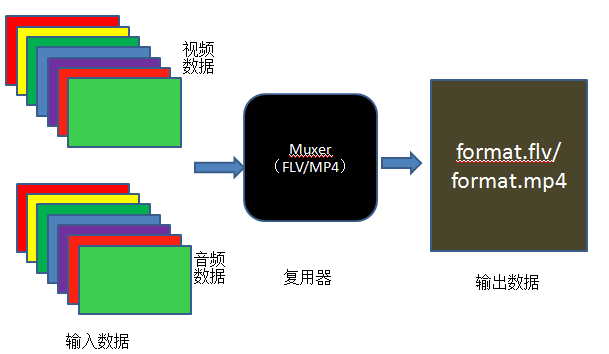
AVOutputFormat*fmt;AVFormatContext*oc;/* allocate the output media context */avformat_alloc_output_context2(&oc,NULL,NULL,filename);if(!oc){printf("Could not deduce output format from file extension: using MPEG.\n");avformat_alloc_output_context2(&oc,NULL,"mpeg",filename);}if(!oc)return1;fmt=oc->oformat;
该函数调用完成后,一个新的 AVStream 便已经加入到输出文件中,下面就需要设置 stream 的 id 和 codec 等参数。以视频流为例,代码如下:
12345678910111213
OutputStream*ost;AVFormatContext*oc;AVCodec**codec;AVCodecContext*c;AVStream*st;st=avformat_new_stream(oc,*codec);if(!st){fprintf(stderr,"Could not allocate stream\n");exit(1);}st->id=oc->nb_streams-1;c=st->codec;
//open the codecret=avcodec_open(c,codec,&opt);if(ret<0){fprintf(stderr,"Could not open video codec: %s\n",av_err2str(ret));exit(1);}//allocate and init a re-usable frameost->frame=alloc_picture(c->pix_fmt,c->width,c->height);
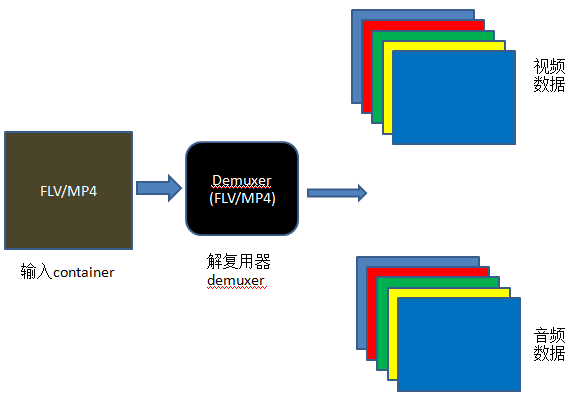
//open input file, and allocate format contextif(avformat_open_input(&fmt_ctx,src_filename,NULL,NULL)<0){fprintf(stderr,"Could not open source file %s\n",src_filename);exit(1);}//retrive stream informationif(avformat_find_stream_info(fmt_ctx,NULL)<0){fprintf(stderr,"Could not find stream information\n");exit(1);}
staticintopen_codec_context(int*stream_idx,AVFormatContext*fmt_ctx,enumAVMediaTypetype){intret,stream_index;AVStream*pStream;AVCodecContext*codec_ctx=NULL;AVCodec*codec;ret=av_find_best_stream(fmt_ctx,type,-1,-1,NULL,0);if(ret<0){fprintf(stderr,"Could not find %s stream in input file '%s'\n",av_get_media_type_string(type),src_filename);}else{stream_index=ret;pStream=fmt_ctx->streams[stream_index];//find decoder for the streamcodec_ctx=pStream->codec;codec=avcodec_find_decoder(codec_ctx->codec_id);if(!codec){fprintf(stderr,"Failed to find %s codec\n",av_get_media_type_string(type));returnAVERROR(EINVAL);}//open the decoderif((ret=avcodec_open2(codec_ctx,codec,NULL))<0){fprintf(stderr,"Failed to open %s codec\n",av_get_media_type_string(type));returnret;}}*stream_idx=stream_index;}
针对音频、视频,分别调用该函数,示例代码如下:
123456789101112131415161718192021
if(open_codec_context(&video_stream_idx,fmt_ctx,AVMEDIA_TYPE_VIDEO)>=0){video_stream=fmt_ctx->streams[video_stream_idx];video_codec_ctx=video_stream->codec;//allocate image where the decoded image will be putwidth=video_codec_ctx->width;height=video_codec_ctx->height;pix_fmt=video_codec_ctx->pix_fmt;ret=av_image_alloc(video_dst_data,video_dst_linesize,width,height,pix_fmt,1);if(ret<0){fprintf(stderr,"Could not allocate raw video buffer\n");exit(1);}video_dst_bufsize=ret;}if(open_codec_context(&audio_stream_idx,fmt_ctx,AVMEDIA_TYPE_AUDIO)>=0){audio_stream=fmt_ctx->streams[audio_stream_idx];audio_codec_ctx=audio_stream->codec;}
staticintdecode_packet(int*got_frame,intcached){intret=0;intdecoded=pkt.size;*got_frame=0;if(pkt.stream_index==video_stream_idx){//decode video frameret=avcodec_decode_video2(video_codec_ctx,frame,got_frame,&pkt);if(ret<0){fprintf(stderr,"Error decoding video frame (%s) \n",av_err2str(ret));returnret;}printf("num %d got_frame %d\n",num++,*got_frame);if(*got_frame){av_image_copy(video_dst_data,video_dst_linesize,(constuint8_t**)(frame->data),frame->linesize,pix_fmt,width,height);//write to raw video filefwrite(video_dst_data[0],1,video_dst_bufsize,video_dst_file);}}elseif(pkt.stream_index==audio_stream_idx){//decode audio frameret=avcodec_decode_audio4(audio_codec_ctx,frame,got_frame,&pkt);if(ret<0){fprintf(stderr,"Error decoding audio frame (%s)\n",av_err2str(ret));returnret;}if(*got_frame){size_tunpadded_linesize=frame->nb_samples*av_get_bytes_per_sample(frame->format);fwrite(frame->extended_data[0],1,unpadded_linesize,audio_dst_file);}}returnFFMIN(ret,pkt.size);}//allocate frame frame=av_frame_alloc();if(!frame){fprintf(stderr,"Could not allocate frame\n");exit(1);}av_init_packet(&pkt);pkt.data=NULL;pkt.size=0;//read frames from the fileintgot_frame;while(av_read_frame(fmt_ctx,&pkt)>=0){AVPacketorig_pkt=pkt;do{ret=decode_packet(&got_frame,0);if(ret<0)break;pkt.data+=ret;pkt.size-=ret;}while(pkt.size>0);av_free_packet(&orig_pkt);}