基于上下文的自适应二进制算术编码(CABAC)是 ITU-T/ISO/IEC 视频压缩标准 H.264/AVC 的一个标准部分。通过将自适应二进制算术编码技术与上下文建模相结合,实现了高度的自适应并降低冗余。CABAC 框架还包括一种用于用于二进制算术编码和概率估计的新的低复杂度方法,非常适合高效的硬件和软件实现。对于预期目标应用的典型领域,CABAC 显著优于H.264/AVC的 baseline 熵编码方法。对于代表广播应用中使用的典型材料的一组测试序列,以及大约30到38 dB 的可接受视频质量范围,平均比特流节省9%-14%。
CABAC 框图
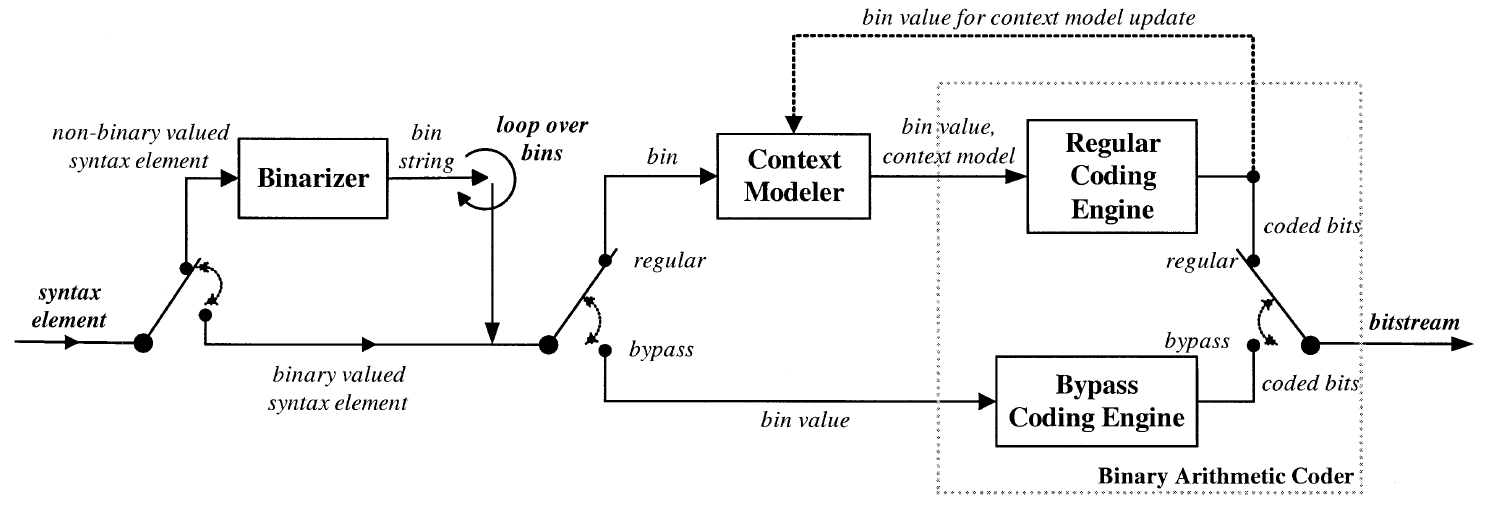
图1显示了在 CABAC 中编码单个语法元素的通用框图。编码过程最多由三个基本步骤组成:1) 二值化 2)上下文建模 3)二进制算术编码
第一步中,将给定的非二进制值语法元素唯一地映射到二进制序列,即所谓的 bin string。当给定一个二进制语法元素时,这个初始步骤被忽略,如图 1 所示。对于 bin string 的每个元素或每个二进制语法元素,根据编码模式可能会遵循一个或两个后续步骤。
在所谓的常规编码模式中,在实际算术编码过程之前,给定的二进制决策(在下文中,我们称之为bin)进入上下文建模阶段,在此阶段选择概率模型,以便相应的选择可能取决于先前编码的语法元素或bin。然后,在分配上下文模型之后,bin 值及其相关模型被传递到常规编码引擎,在该引擎中进行算术编码的最后阶段以及随后的模型更新(参见图1)。
或者,为所选择的bins选择 bypass编码模式,以便通过简化的编码引擎而不使用明确分配的模型来允许整个编码(和解码)过程的加速,如图1中开关的右下分支所示。
接下来,将更详细地讨论三个主要功能构建块,即二值化、上下文建模和二值算术编码,以及它们之间的相互依赖关系。
A. 二值化
1) 普通方法:为了在视频编码中成功应用上下文建模和自适应算术编码,我们发现应满足以下两个要求:
a) 条件概率的快速和准确估计,必须在 slice 编码单元的相对较短的时间间隔内实现。
b) 执行概率估计和后续算术编码的每个基本操作所涉及的计算复杂度,必须保持在最低水平,以促进这些固有的顺序组织过程的足够高的吞吐量。
为了满足这两个要求,我们引入了重要的”预处理”步骤,即首先减少要编码的语法元素的字母表大小。CABAC 中的字母表缩减是通过对每个非二进制语法元素应用二值化方案来执行的,从而给定语法元素生成唯一的中间二进制码字,称为二进制字符串。这种方法的优点在于建模和实现。
首先,重要的是要注意,在建模方面没有任何损失,因为可以通过使用 bin 字符串的各个 bin 的概率来恢复单个(非二进制)符号概率。为了说明这一点,让我们考虑P/SP slice的语法元素mb_type的二值化。
如图2(a)所示,二叉树的终端节点对应于语法元素的符号值,使得用于从根节点到对应终端节点遍历树的二进制决策的串联表示对应符合值的 bin 字符串。例如,假定mb_type的值为3,它指示宏块类型为 P_8x8,即宏块在 P/SP slice 中划分为四个 8x8 自宏块,在这种情况下,对应的 bin 字符串由 001 给出。结果显而易见,符号概率p(“3”)等于这些概率p(C0)(“0”)、p(C1)(“0”)、p(C2)(“1”)的乘积,其中C0,C1和C2表示相应内部节点(二进制)概率模型,如图2所示。这种关系对于任何这样的二叉树表示的任何符号都是正确的,可以通过迭代应用全概率定理来推导。
虽然在这一阶段似乎什么也得不到,但在bin字符串上使用二进制算术编码引擎,而不是在原始 m 进制源字母表上使用 m 进制算术编码器,已经有了优势。自适应 m 进制算术编码(对于m > 2)通常是一种计算复杂的操作,它要求至少对每个符合进行两次乘法编码,以及许多相当复杂的操作来执行概率估计的更新。与此相反,二进制算术编码存在快速、无乘法的变体,其中一种是专门为 CABAC 框架开发的,如下所述。由于具有较大 bin 字符串的符号的概率通常非常低,因此在 m 元算术编码器中,对该 bin 字符串的所有bin进行编码,而不是仅使用一次过程的计算开销相当小,并且可以通过使用快速二进制编码引擎来进行补偿。
最后,作为最重要的优势,二值化支持在字符号级别上进行上下文建模。对于通常由最常观测的 bin 表示的特定 bin,可以使用条件概率,而其他通常不太常观测的 bin 可以使用联合(通常为零阶)概率模型处理。与在具有典型大字母表大小的源的原始域中使用上下文模型的传统方法相比(例如,运动矢量差的分量或变换系数水平),设计中的这种额外自由度提供了一种灵活的工具,用于使用高阶条件概率,而无需受到语境“稀释”效应的影响。这些影响通常在以下情况下观察到:大量条件概率必须在相对较小的(编码)时间间隔内自适应估计,因此没有足够的样本来达到每个模型的可靠估计。
CABAC(Context-Based Adaptive Binary Arithmetic Coding) 主要包括三步:二值化、上下文建模、二进制算术编码。