在 HM 的源码分析中,经常会用到读取 syntax 值,此时用到 xReadCode xReadUvlc xReadSvlc xReadFlag 的函数,这篇就主要分析这几个函数的源码。
对 syntax 的分析,主要是由SyntaxElementParser完成,位于lib\libdecoder\SyntaxElementParser.h中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
其实读取 syntax 值的这几个函数,主要是 SPEC 中第 9 部分的代码实现。这几个函数共同调用了Read函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 | |
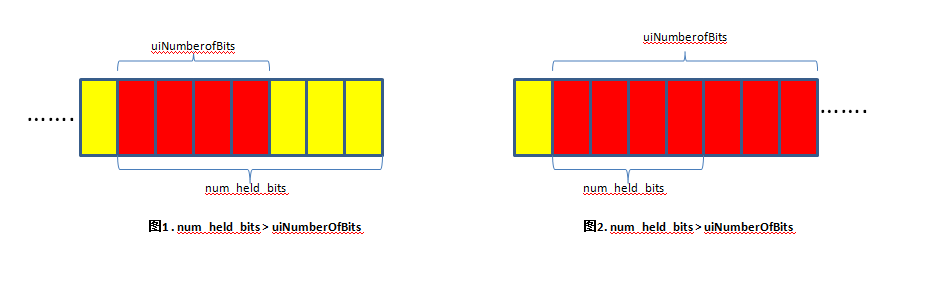
关于read函数其实主要分为两大来,一类是 numberofbits < num_held_bits,此时
只要通过简单的将 held_bits 左右移外加mark动作就能够把该syntax的值获得。如图1.
另一类则是 numberofbits > num_held_bits 时,需要重新加载新的bitstream进来,并根据 numberofbits 和 num_held_bits 差值的大小决定
加载几个 byte。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 | |
其中的xReadCodexReadFlag很好理解,此处不在说明,xReadUvlc和xReadSvlc分别是处理0阶指数哥伦布编码中对 ue(n) he
se(n) 解析。该部分主要在 SPEC 的9.2 节。
1 2 3 4 5 | |
spec 中关于 ue 和 se 的计算有如下描述:
Depending on the descriptor, the value of a syntax element is derived as follows: If the syntax element is coded as ue(v), the value of the syntax element is equal to codeNum. Otherwise , the value of the syntax element is derived by invoking the mapping process for signed Exp-Golomb codes as specified in clause 9.2.2 with codeNum as input.
关于 UE 和 SE 中关于 bit 和 syntax value 的对应关系如下:
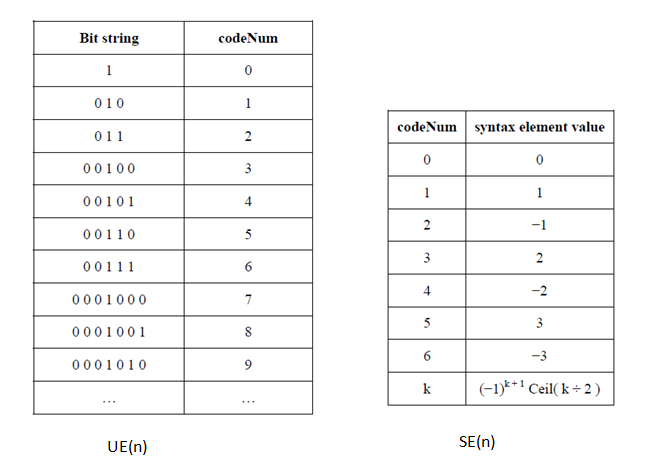
与SyntaxElementParser相对应的是SyntaxElementWrite,其中包含了xWriteCode xWriteUvlc xWriteSvlc xWriteFlag四个函数。此处不在分析。