DAV1D 作为 AV1 最高效的解码器,仍然有可优化的空间,根据自己的理解,可执行的优化方案大概从三个方面实现:程序流程、算法实现、编程语言三个角度进行优化。
程序流程
DAV1D 解码器的流程如下图所示:
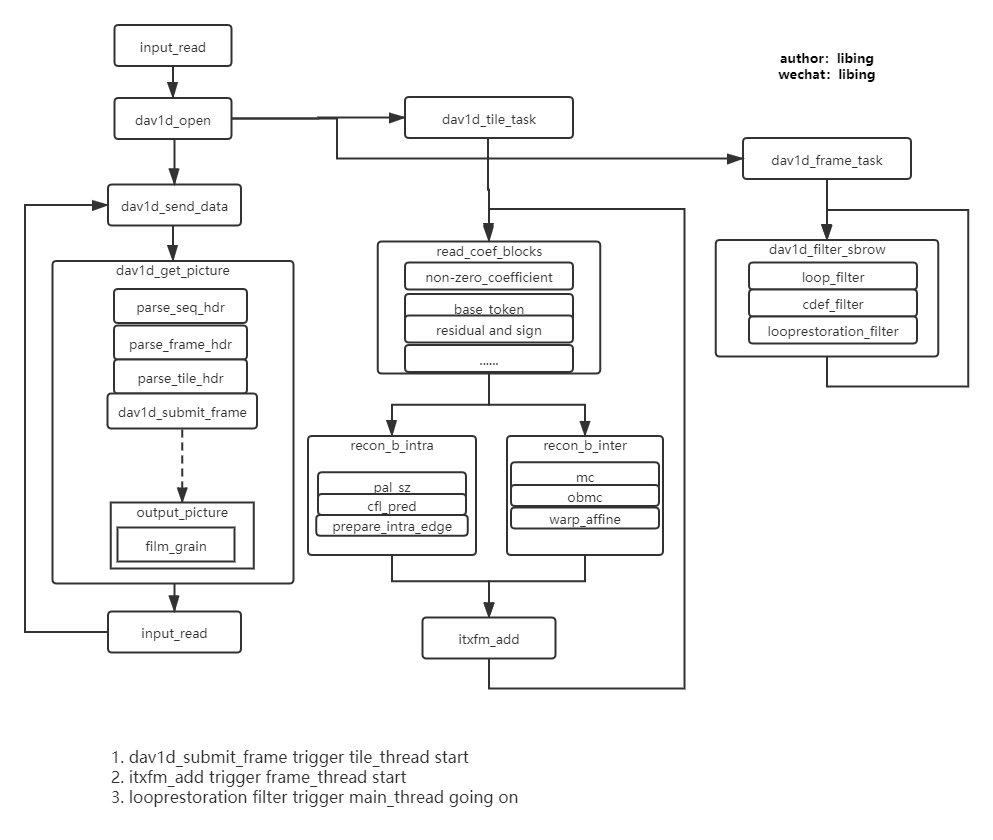
从图中可以看出,DAV1D 解码器本身有三个线程,Main Thread、Frame Thread 和 Tile Thread。
- Main Thread 主要控制整个解码流程,包括读取数据、Parse Obu Header(Sequence、Frame、Tile)、Film Grain、将AV1 数据给到另外两条 Thread、写数据。
- Tile Thread 主要完成重建帧部分,包括read_coef_blocks、recon_b_intra/recon_b_inter、itxfm_add。
- Frame Thread 主要完成滤波部分,是在一帧内,所有的Tile 解码完成后,Loop Filter、CDEF Filter、LoopRestoration Filter。
分析上面的流程可以看出 Film Grain 部分,属于后处理部分,不会影响到其他帧的解码,因此,可以将 Film Grain 部分单独创建一个 Thread 来实现。这条优化肯定是可以实现的,只是代码库中还没有实现。
另外,Frame Thread 主要包括三种滤波:Loop Filter 、CDEF Filter、LoopRestoration Filter 三种,而且是顺序执行,因此可以考虑将这三种滤波,用不同的 Thread 实现。
算法实现
1. 局部性原理用在 LoopRestoration 中。
LoopRestoration_tmpl.c 中,维纳滤波的实现有如下一段代码:
1 2 3 4 5 6 7 8 9 10 11 12 | |
上面的实现是按照列实现完成的,其实硬件的存储结构导致,行实现完成效率更高。
1 2 3 4 5 6 7 8 9 10 11 12 | |
2. 局部性原理用在 Film Grain 优化。
Film Grain 的流程主要包括两部分:1. 从 Grain_lut 中获取 grain值。2. 通过获取的 grain 值,执行 add_noise_y。
因为获取 grain 值时,访问的内存是不连续的。此时可以考虑,先将获取的grain 值存起来,放到一块连续的buffer中,之后在执行 add_noise_y 的操作。 实现完上述步骤后,可以利用这种方式继续执行,继续使用 NEON 优化。
测试下来发现,960x540 分辨率,解码模块耗时 8ms,利用局部性原理优化完成后,该模块耗时 7ms,使用NEON优化后,该模块耗时5ms。
这还只是优化了 Y 方向的计算,如果后续优化完成 UV 方向的计算后,效果会更加明显。
编程语言
SIMD 指令优化,在编解码中一直起着非常非常重要的作用,这也解释了为什么所有的编解码器,都有 SIMD 指令的优化,可以说,SIMD 指令优化是仅次于线程优化的方案了。 在 DAV1D 最初的版本中,还不支持持 10 bit汇编的情况下,自己手动实现了 LoopFilter、CDEF Filter、LoopRestoration Filter、Film Grain Filter、MC 等模块后,解码效率提升了150%-200%。这还是在没实现 IDXT 模块的前提下。如果将所有能够使用SIMD指令优化的结果,都实现了,预估应该能做到 200%-250% 的解码效率。
绝大多数的 NEON 汇编优化,核心代码都可以简化为如下模式:
1 2 3 | |
使用 NEON 汇编优化上面的代码实现,假设 src1 的地址在寄存器 x0 中,src2 的地址在寄存器 x2 中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |