Film Grain在电视和电影内容中广泛存在,它经常是创作内容的一部分,在编码过程中需要保留下来,因为film grain的随机性,导致很难用传统的压缩算法进行压缩。
Film Grain 简介
film grain模型和整体框架如图所示。
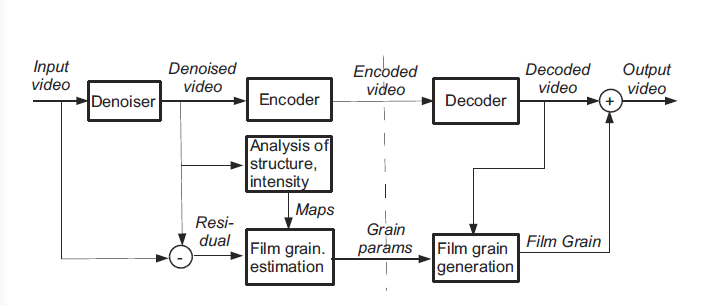
film grain在去噪音过程中会从视频中去除掉,grain参数会通过噪音视频序列和去噪视频序列的差异中获得,这些参数会和压缩视频流一起传输到解码端。 解码后,film grain会被叠加到重建视频帧中。
Film Grain 流程
从上面的框架图可以看出,film grain包括压缩前的去噪、编码参数、解码参数、噪音叠加到重建帧等几个过程,这里不讨论去噪的过程,主要讨论film grain modeling synthesis。
流程可以从SPEC中看到,也可以从源码中学习,film grain中在源码中主要集中在aom/aom_dsp/grain_synthesis.c中的av1_add_film_grain_run函数中,分析源码可知大致分为如下流程:
- init_array. 为
film grain准备后面用到的内存,大致分为三类grain buffer(luma_grain_block/cb_grain_block/cr_grain_block)、line buf(y_line_buf/cb_line_buf/cr_line_buf)、column buf(y_col_buf/cb_col_buf/cr_col_buf)。
- generate_luma_grain_block 和 generate_chroma_grain_blocks. 它会根据码流中 parse 出来的
grain_scale_shift/ar_coeff_lag的值和gaussian_sequence表来填充grain block。
- init_scaling_function. 它是利用码流中 parse 出来的
scaling_points_y来填充scaling_lut_y/scaling_lut_cb/scaling_lut_cr数组。
- add_noise_to_block。它会根据上面生成的
grain block叠加到重建帧上。
源码分析及优化
以解码器 DAV1D 中 Film Grain 的源码分析。首先看 Y 方向上的主要代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| // samples from the correct block of a grain LUT, while taking into account the
// offsets provided by the offsets cache
static inline entry sample_lut(entry grain_lut[GRAIN_HEIGHT][GRAIN_WIDTH],
int offsets[2][2], int subx, int suby,
int bx, int by, int x, int y)
{
const int randval = offsets[bx][by];
const int offx = 3 + (2 >> subx) * (3 + (randval >> 4));
const int offy = 3 + (2 >> suby) * (3 + (randval & 0xF));
return grain_lut[offy + y + (BLOCK_SIZE >> suby) * by]
[offx + x + (BLOCK_SIZE >> subx) * bx];
}
#define add_noise_y(x, y, grain) \
pixel *src = src_row + (y) * PXSTRIDE(stride) + (bx + (x)); \
pixel *dst = dst_row + (y) * PXSTRIDE(stride) + (bx + (x)); \
int noise = round2(scaling[*src] * (grain), data->scaling_shift); \
*dst = iclip(*src + noise, min_value, max_value);
for (int y = ystart; y < bh; y++) {
// Non-overlapped image region(straightforward)
for (int x = xstart; x < bw; x++) {
int grain = sample_lut(grain_lut, offsets, 0, 0, 0, 0, x, y);
add_noise_y(x, y, grain);
}
}
|
上面的代码主要包含两部分,一. 从 grain_lut 中获取 grain,二. 通过获取的 grain 值,执行 add_noise_y。分析代码,如果想要利用 NEON 进行汇编优化,
存在一个问题,就是无法连续的从 grain_lut 中连续的获取值,因此直接按照源码的流程,无法进行 NEON 优化。考虑到硬件的 cache 原理,可以先将
所有的 grain 值提前提取出来放到数组中,之后在进行 add_noise_y 时,就可以连续的获取 grain 值了。从程序上看,该方法没有任何作用,因为执行的代码
是相同的,但硬件是有cache的,因此,可以提升性能。也为后面的 NEON 提供了遍历。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| #define add_noise_y(x, y, grain) \
pixel *src = src_row + (y) * PXSTRIDE(stride) + (bx + (x)); \
pixel *dst = dst_row + (y) * PXSTRIDE(stride) + (bx + (x)); \
int noise = round2(scaling[*src] * (grain), data->scaling_shift); \
*dst = iclip(*src + noise, min_value, max_value);
int *grain = (int *)malloc(sizeof(int)* (bh - ystart) * (bw - xstart));
for (int y = ystart; y < bh; y++){
for (int x = xstart; x < bw; x++)
grain[y][x] = sample_lut(grain_lut, offsets, 0, 0, 0, 0, x, y);
}
for (int y = ystart; y < bh; y++) {
// Non-overlapped image region(straightforward)
for (int x = xstart; x < bw; x++) {
add_noise_y(x, y, grain[y][x]);
}
}
|
上面代码优化前,解码 960x540 的分辨率率的视频,该模块耗时 8ms,C 代码优化完后,该模块耗时 7ms。在此基础上,进行 NEON 优化,该模块耗时 5ms。
参考文档
- AV1 Bitstream & Decoding Process
(未完待续…)